

Wenn Sie sich je gefragt haben, wie Tausende echter menschlicher Stimmen klingen — unterschiedliche Altersgruppen, Akzente, Sprachen — dann gibt es dafür einen Datensatz. Er heißt Mozilla Common Voice und ist eine der größten offenen Sammlungen aufgezeichneter Sprache der Welt.
Menschen aus aller Welt lesen freiwillig Sätze vor und spenden ihre Aufnahmen. Das Ergebnis ist eine riesige, mehrsprachige Bibliothek echter Stimmen — frei verfügbar für alle.
Es gibt nur ein Problem: Sie wirklich zu erkunden, ist schwierig.
Der Datensatz ist riesig, die Werkzeuge sind es nicht
Common Voice enthält Millionen von Audioclips in Dutzenden von Sprachen. Um ihn durchzusehen, müssten Sie normalerweise Gigabytes an Daten herunterladen, Skripte zum Auswerten der Metadatendateien schreiben und Ihre eigene Wiedergabe-Pipeline einrichten. Das ist in Ordnung, wenn Sie Entwicklerin oder Entwickler sind, aber es sperrt alle anderen aus — Forschende, Sprachwissenschaftlerinnen, Produktteams und neugierige Menschen, die einfach nur hören wollen, wie die Daten klingen.
Wir fanden, das war eine verpasste Gelegenheit.
Also haben wir Common Voice Explorer gebaut
Common Voice Explorer ist ein einfaches Web-Werkzeug, mit dem Sie den Datensatz direkt im Browser durchstöbern können. Kein Download, keine Skripte, keine Einrichtung.
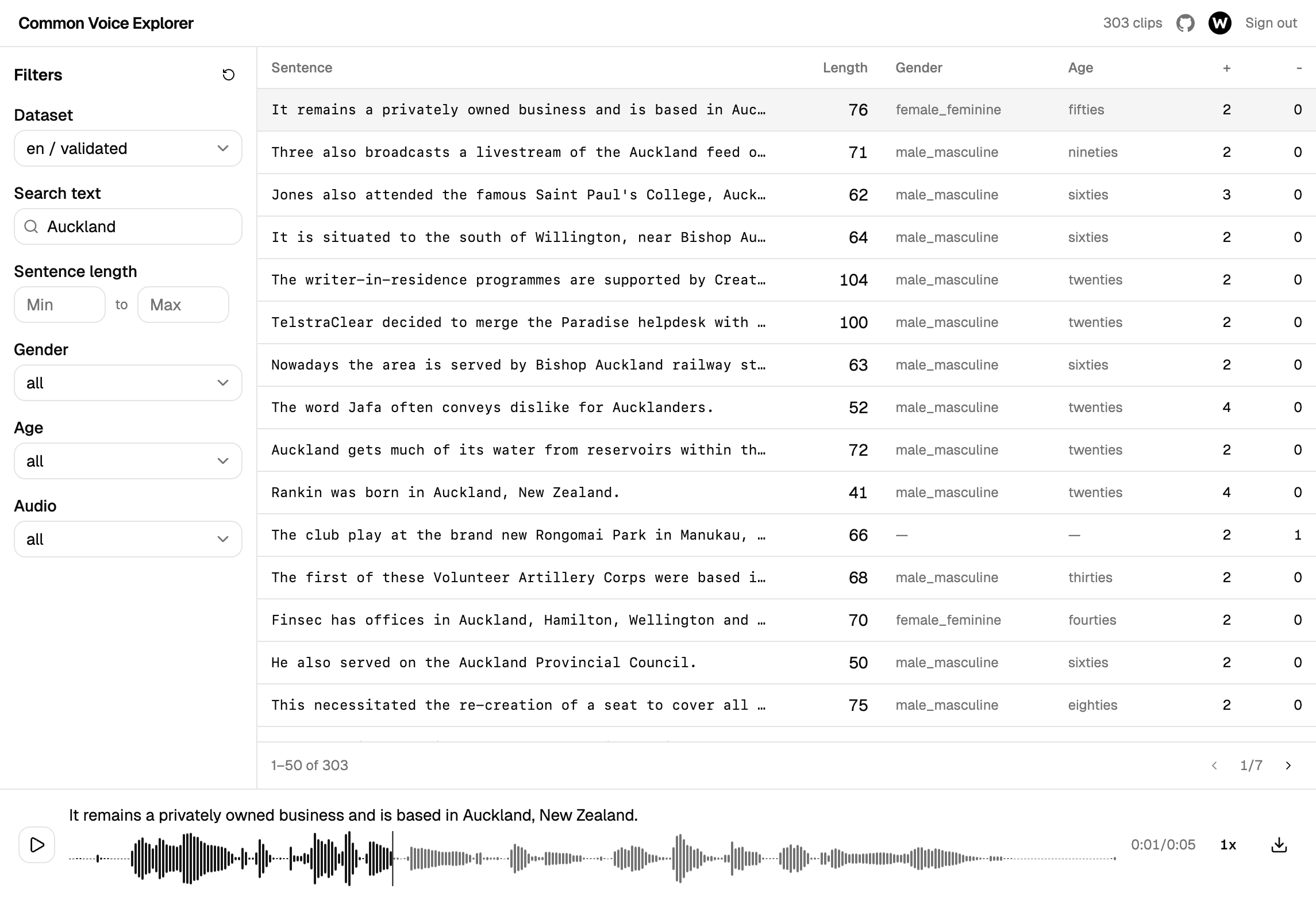
Das können Sie tun:
- Nach Satz suchen — geben Sie ein Wort oder eine Wendung ein und finden Sie sofort Clips, die sie enthalten
- Nach sprechender Person filtern — grenzen Sie die Ergebnisse nach Geschlecht, Altersgruppe oder Sprache ein
- Nach Länge filtern — finden Sie kurze oder lange Sätze, je nachdem, was Sie brauchen
- Sofort anhören — klicken Sie auf einen beliebigen Clip und hören Sie ihn mit visueller Wellenform, passen Sie die Wiedergabegeschwindigkeit an, spulen Sie vor oder zurück
- Clips herunterladen — speichern Sie einzelne Aufnahmen zur Offline-Durchsicht
Es ist so gestaltet, dass es sich anfühlt, als würden Sie eine Musikbibliothek durchstöbern — nur dass Sie statt Liedern echte Sprache von echten Menschen aus aller Welt erkunden.
Für wen ist das gedacht?
Ehrlich gesagt — für alle, die neugierig auf Sprachdaten sind.
- Forschende, die Sprechmuster, Akzente oder sprachliche Vielfalt untersuchen
- Produktteams, die prüfen, ob Common Voice ihren Anforderungen entspricht, bevor sie sich festlegen
- Sprachwissenschaftlerinnen und Lehrende, die nach authentischen gesprochenen Beispielen suchen
- Entwicklerinnen von Sprach-KI, die schnell die Datenqualität überprüfen wollen
- Alle, die es einfach faszinierend finden zu hören, wie unterschiedliche Menschen denselben Satz sagen
Sie müssen kein technisches Wissen mitbringen, um es zu nutzen. Wenn Sie eine Suchleiste bedienen und auf Wiedergabe klicken können, sind Sie startklar.
Warum es uns wichtig ist
Bei WaveKat bauen wir Sprach-KI-Werkzeuge für kleine Unternehmen. Diese Arbeit hängt von hochwertigen Sprachdaten ab. Common Voice ist eine der wichtigsten offenen Ressourcen in diesem Bereich, und wir sind überzeugt, dass es allen zugutekommt, sie zugänglicher zu machen — nicht nur den Entwicklerinnen und Entwicklern.
Offene Daten haben nur dann einen Wert, wenn Menschen sie tatsächlich erkunden können. Genau diese Lücke wollten wir schließen.
Probieren Sie es aus
Common Voice Explorer ist live unter commonvoice-explorer.wavekat.com. Melden Sie sich mit GitHub an, akzeptieren Sie die Nutzungsbedingungen und legen Sie los.
Es gibt außerdem eine kurze Demo auf YouTube, falls Sie es zuerst in Aktion sehen möchten.